my aim was to try recreating a simple GPT model without any API calls or anything, of course the latest models are insanely good they can search web, reason with themselves, we are gonna try creating a simple transformer on which models like openai, claude are based
I didn't have that much time / compute to do something that crazy so whatever you'll see is like a small miniature version I tried replicating on my small macbook (M2 Air 8gb variant)
alright I started by watching Andrej Karpathy's this video https://youtu.be/kCc8FmEb1nY and to be frank this article won't be possible without this video, half of the things i'll talk about are things i learned from this video or the research papers he mentioned
I'm gonna tell main crux of the video and how i enhanced it, if you want a full video watch Karapathy's video, he has explained very nicely there
anyways before we begin i scraped all of my https://shrit.substack.com/ substack posts which I have been for two years and anything else I had on the internet, in the initial attempt when I fully trained the model the responses were something like
text
Me: who is shrit
ShritGPT: is study newsletter building so for properly not insane more study ships so intell and easy something cooking and hard problem. is hard problem. good problem dumb. one outreach is
which if u think is pretty cool that it can form words which are actually not in the training data, but it's really really wrong so I had go and add small section such as dm answers for tokens to more about me more easily
i personally don't like to use much filler words when talking to someone on text, if u want u can add filler words
I had roughly 1000029 characters in my data, i recommend something around 1-1.2million characters to have as a data
Interpreting the data
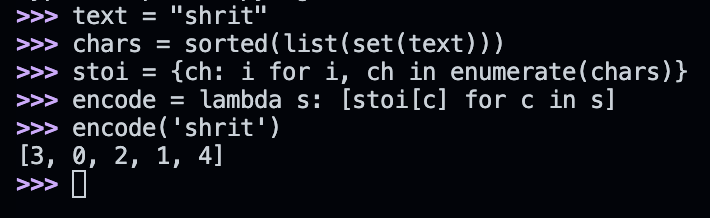
we can't really put so much text data files in the model and be like predict next token, we have to encode strings to make it into simple numbers so it's easy to read
Encoding / Decoding
we need method to encode and decode our data, openai using https://github.com/openai/tiktoken this library to encode & decode, for us simply doing this will work since we have very small data
Tokenizer Playgroundvocab: 99 · len: 18
t
20
h
8
e
5
m
13
:
44
·
0
w
23
h
8
o
15
·
0
i
9
s
19
·
0
s
19
h
8
r
18
i
9
t
20
hover a token to see its integer ID · spaces shown as · · real model uses 99-char vocab from sorted(set(corpus))
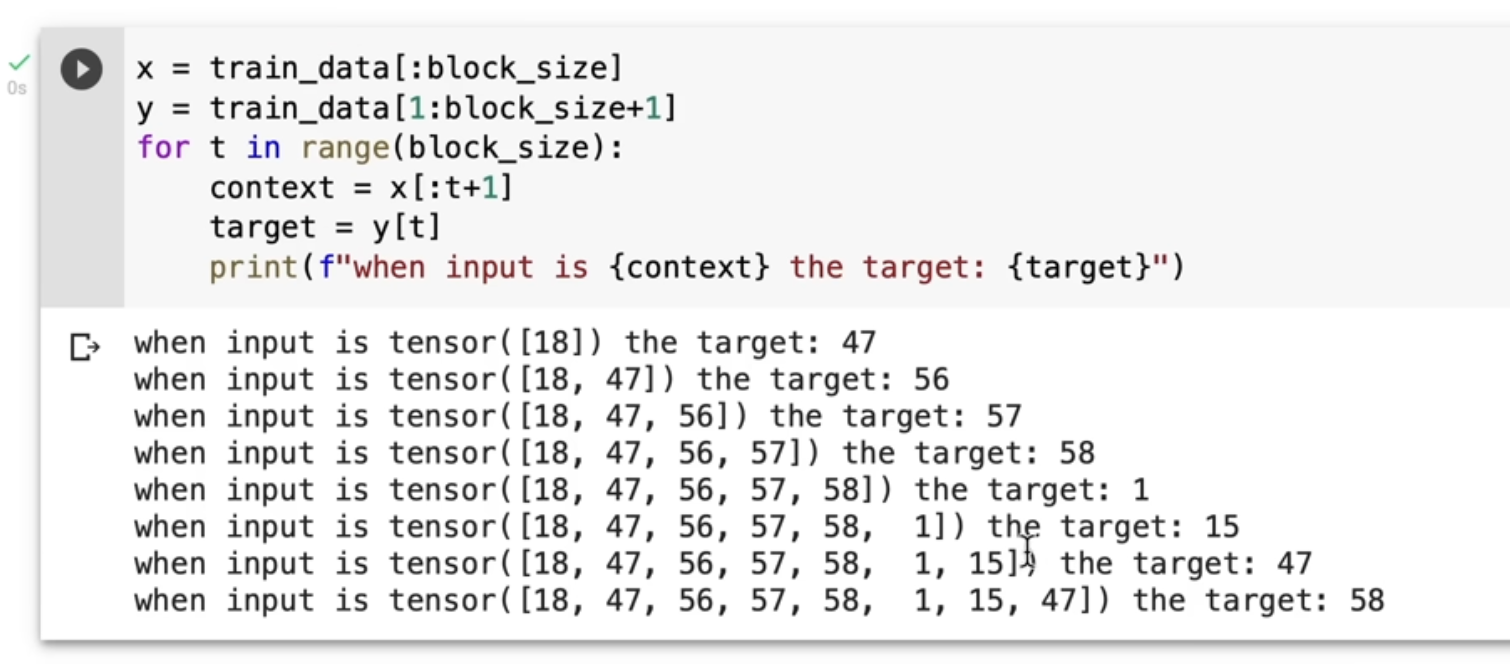
Data Loading
After splitting 90% of data for training we want our model to predict the next character, in the world of transformers we call them token, we wanted something to test and train our data so we try to train the model with the possible targets of the token
Training The Model (Bigram Language Model)
In order to train our data we want model to look at previous values as well, in most simplest form Bigram Language Model, it looks at the previous token and try to generate the next token
it takes input in something known as BTC - Batch, Time, Channel, and output in logits(raw scores from neural network) and loss(deviation with mode prediction and value, it updates model weights)
this model is actually logic for how character sequences are predicted
We are using AdamW as training loop for the model, calculating train loss and val loss, more closer these both values more better
Note: with Bigram model even though we take all the previous tokens to in our memory, only the last token is used to predict the next, this is inefficient
this is our basic and simplest way to make a transformer, however if u run this you'll be nowhere close to the output, you'll still get some gibberish
we're on theory done with the model, but the model isn't that powerful to produce some nice output, so we're gonna try making it more optimized so as to see some results
Bigram Prediction Table
m
e
t
h
:
m
2
72
4
3
3
16
e
4
5
6
7
62
16
t
3
5
4
76
3
9
h
8
62
4
3
3
20
:
2
3
2
2
1
90
28
12
22
8
2
28
high problow probtop-3
click a row label to see the top-3 most likely next characters · tuned to the DM corpus — every line starts me: or them:
Self Attention
we want our model to utilize our memory of tokens, with our model we will want to use all our tokens to give as much information as possible, so self attention allows us to talk to diffrent tokens
so how do we do it?
we want tokens to prevent looking at the future so we usually use a triangular mask to hide any future data
Every token at every position produces two vectors, key and pair
we dot product of one query and key of all others
By Applying softmax function we calculate the weighted sum which is much better than just finding the average
then we divide it by root of head size (dk), this is called scaled attention it's a important normalization which has to be done
Attention(Q,K,V)=softmax(dkQKT)V
these values are known as weights, one of another crucial aspects of our model. we calculate attention in our Head class (forward function)
you'll see train loss an value loss to be more less, that's an imporvement there.
Self-Attention Heatmap
them
:
who
is
shrit
?
me
:
them
100
×
×
×
×
×
×
×
:
45
55
×
×
×
×
×
×
who
10
15
75
×
×
×
×
×
is
8
52
35
×
×
×
×
shrit
8
30
28
28
×
×
×
?
10
10
42
28
×
×
me
30
32
8
8
10
×
:
8
10
38
22
high attentionlow attention× masked (future)
hover a row to see its attention pattern · toggle to see the ÷√dk smoothing effect · scaled by 1/√64 (head_size = n_embd/n_head = 384/6)
Multi Head Attention
mutlihead attention is basically multiple self attention working in parallel to provide more compute and better results we it in MultiHeadAttention
after implementing this, you'll again see train value and loss value reducing
Multi-Head Attention
click a head tile to expand its full attention pattern · real model: 6 heads × 64-dim each = 384 (concatenated back to n_embd)
Feed Forward
FFN(x)=ReLU(xW1+b1)W2+b2
from experiment we usually find x to be in mutlitple of 4
in simple words we have given data to a token, we want to give time for every token to think, we're giving enough compute to each token so they have enough time to interact with each other
It's a regularization technique where model shuts off a subset of neurons, the model is prevented from relying too heavily on any specific path, which helps to mitigate overfitting when the model is scaled up
Awesome our basic system to make a basic system optimized pipelin for the is done, it looks something like this
Scaling Up
up until now you'll be probably be working with very small set of data, now let's train the full data I had macbook air m2 8gb so my settings were
it took roughly 30 minute and the output was pretty good there were lot of discrepancies but i could see the things being worked on.
Optimizing the model
it works well but we can optimize and show the text more nicely
Fine Tuning
I am basically trying to polish the mode, I tried to decay learning rate to slowly, instead of going straight zero like main model
Temperature & K
After training, the model does not output one fixed next character. It outputs logits — raw scores for every character in the vocab. on a conversational model it often feels too random (weird jumps) or too repetitive (same phrases looping).
I added two knobs on top of that: temperature and top-k.
Lower temperature (e.g. 0.5) → sharper distribution → model sticks to high-probability chars → more focused / conservative replies.
Higher temperature (e.g. 1.0+) → flatter distribution → more creative / chaotic text.
Top k
Even after temperature, the tail of the distribution can still contain thousands of low-probability characters (typos, random symbols). Top-k fixes that by only keeping the k highest logits and zeroing everything else before softmax:
So you only sample from the top 25 (my default) most likely next characters. That cuts a lot of garbage without killing variety completely.
Sampling Playground
T=0.50k=25H=1.72 bitsreal defaults: T=0.5, k=25
0.1 (focused)2.0 (creative)
k=1 (greedy)k=40 (all)
e
t
a
o
i
n
s
h
r
d
l
c
u
m
w
f
g
y
p
b
v
k
j
x
q
z
.
,
!
drag sliders to reshape the distribution · blue bars = within top-k · press sample to draw a character · real sample_next: logits/max(T, 1e-8) → top-k mask → softmax → multinomial
Checkpoint & Point Loss
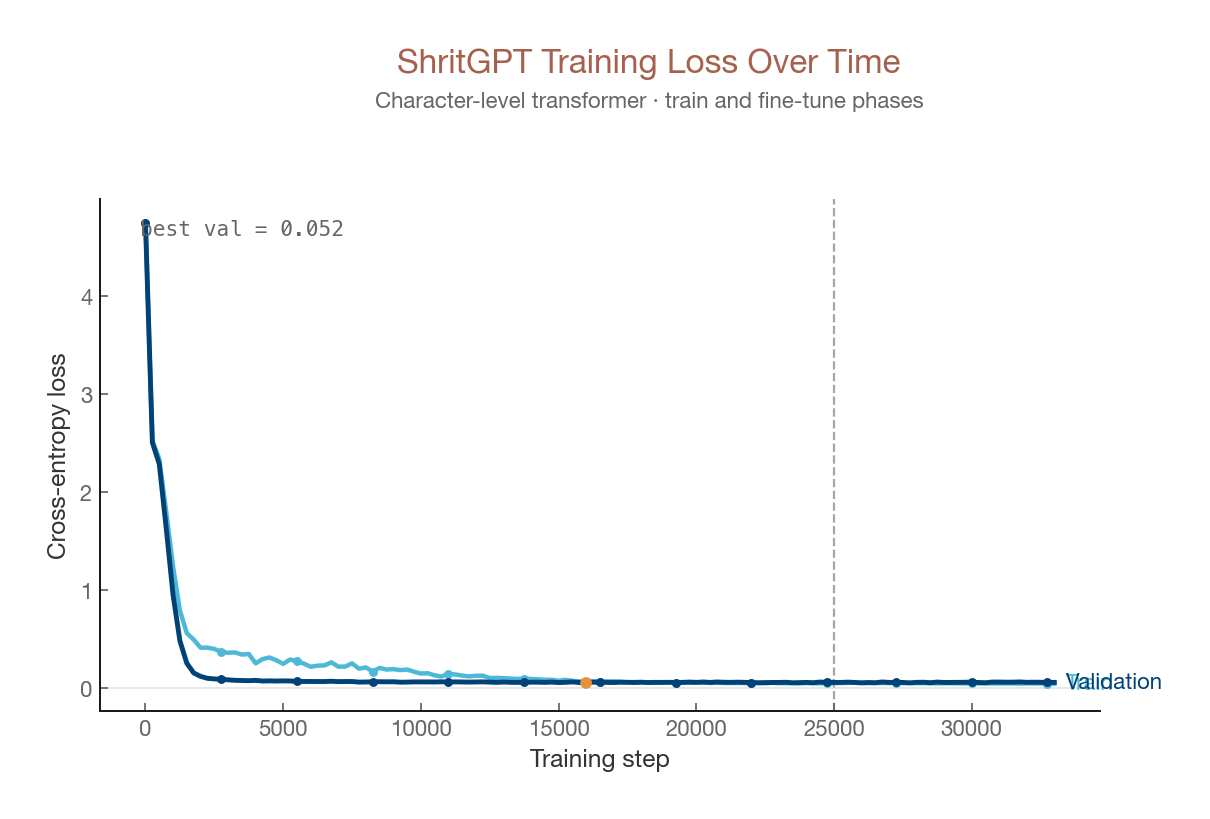
The Final model took ~270 minutes to train & finetune, it was really hard for me, plus if i wanted to keep talking to model with this model i have to wait for another 270min, instead of that I added checkpoints which will save the weights, and started logging the loss with time to generate graphs
Training Loss
hover to read off loss values · toggle fine-tune to see the lower-lr tail · val below train is expected — dropout (p=0.1) only active during training
Web UI
Training in the terminal is fine, but i wanted to make the user experience much better, so a simple api endpoint and a html file by claude made this
API Endpoints
Request Body
json
{"message":"who is shrit","history":[{"role":"user","content":"hey"},{"role":"assistant","content":"yo"}],"temperature":0.5,"top_k":25,"max_tokens":180}
I added generate_stream() so each new character is yielded as it is sampled. Flask wraps that in Server-Sent Events (SSE):
The frontend uses fetch + ReadableStream, parses data: {...} lines, and appends text to the bubble every few characters. If streaming 404s, it falls back to /api/chat.
After doing this changes, it took a whooping ~270 minutes for a full dataset compute in detail, but the results are still better.
Conclusion
We tried creating a small GPT, if u want the full code go to this repo: https://github.com/Shrit1401/ShritGPT, ofcourse even though I smashed everything about myself as data it's still not upto the mark of a proper llm like OpenAI's GPT 3, bcz we had restrain the compute and data, the model base will stay the same, to scale we might add more Notes to compute
The text is producing is not propr he doesn't know anything apart from me and all my details, not even proper english. It was really fun project honestly, a very nice way to know how llms respond